
Svenja Adolphs, English professor and researcher
Svenja Adolphs is an English and Linguistics professor at the University of Nottingham. In her book, Introducing Electronic Text Analysis, she discusses the impact of corpus linguistics on analyzing literary texts. Svenja believes that by analyzing words through corpus linguistics, we can gain a better understanding of the English language. By analyzing certain texts through corpus linguistics, we can also better understand the plot, when the book was written, and more about the authors writing style.
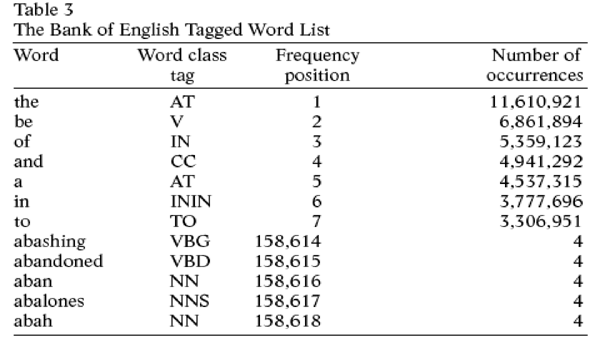
A frequency list from the Bank of English
Within corpora are numerous frequency lists. A frequency list shows either single words or phrases consisting of as many words as the corpus designer desires. These single words or phrases appear in order from top to bottom based on the number of times they appear in the text being analyzed. The figure to the right is an example of a frequency list. The word that appears most is “the” and it occurs 11,610,921 times in all of the works the Bank of English analyzed. The numbers are drawn from multiple works rather than a single source. The figure on the right is a good example of a corpus of singular words.
Why would anyone want to analyze phrases containing multiple words? The words to the left and right of the initial word that was searched for can give a reader the context in which the word was used. If the word “right” were to be searched for, seeing the words around it would help immensely. If the words surrounding “right” weren’t analyzed, the viewer would not know if the author intended for the meaning of the word to be the opposite of left, or a human’s unalienable right given in the constitution.
Using all of the tools corpora provide, viewers can gain a greater understanding of literary work. I know that I’ll be using electronic text analysis in my future research projects and looking at text analysis differently after reading Svenja Adolphs book.














Recent Comments