
I found this graph in the article could “Obesity: Are We Food Obsessed?”. The author wants to use this graph to prove a statement written by Professor Greg Whyte that, when facing with obesity, people are more focused on the diet rather than the physical activity, but they share equal importance.
This graph shows the search rate for the words related to obesity. It is very clean and simple, which gives the audience a direct view at the first glance. For example, we can easily see that diet has the highest rate. However, this graph is not so clearly, which will mislead the audiences.
First, there are two items on the top right – Pubmed and Google. I think these are the two search engines the author wants to focus on. But these two items have two different units, seconds and millions. In my view, million is the for the hit rate. What does seconds stand for confused me a lot.
Second, there are four colors in the graph. Two for Pubmed, two for Google. I’m also wondering, what’s the differences between two colors for the same item. It’s unclear. In other words, the author didn’t give enough information in explaining the meaning of colors.
Third, the title of this graph is missing some parts. The author uses ellipsis after the words ‘Obesity’, which will confuse the audience whether the author is focusing on anything else.
Overall, this is a good graph that clearly shows the results on hits for the search terms. It tells the audiences what the author is looking for, why he thinks in that way and how the results prove the statement. This graph also leads the audience to think in a different way that they focus more on the diet when losing the weight than doing the physical exercises, which might not be right.
Source : http://blogs.discovermagazine.com/neuroskeptic/2012/03/24/obesity-are-we-food-obsessed/#.WOwDslPys_W




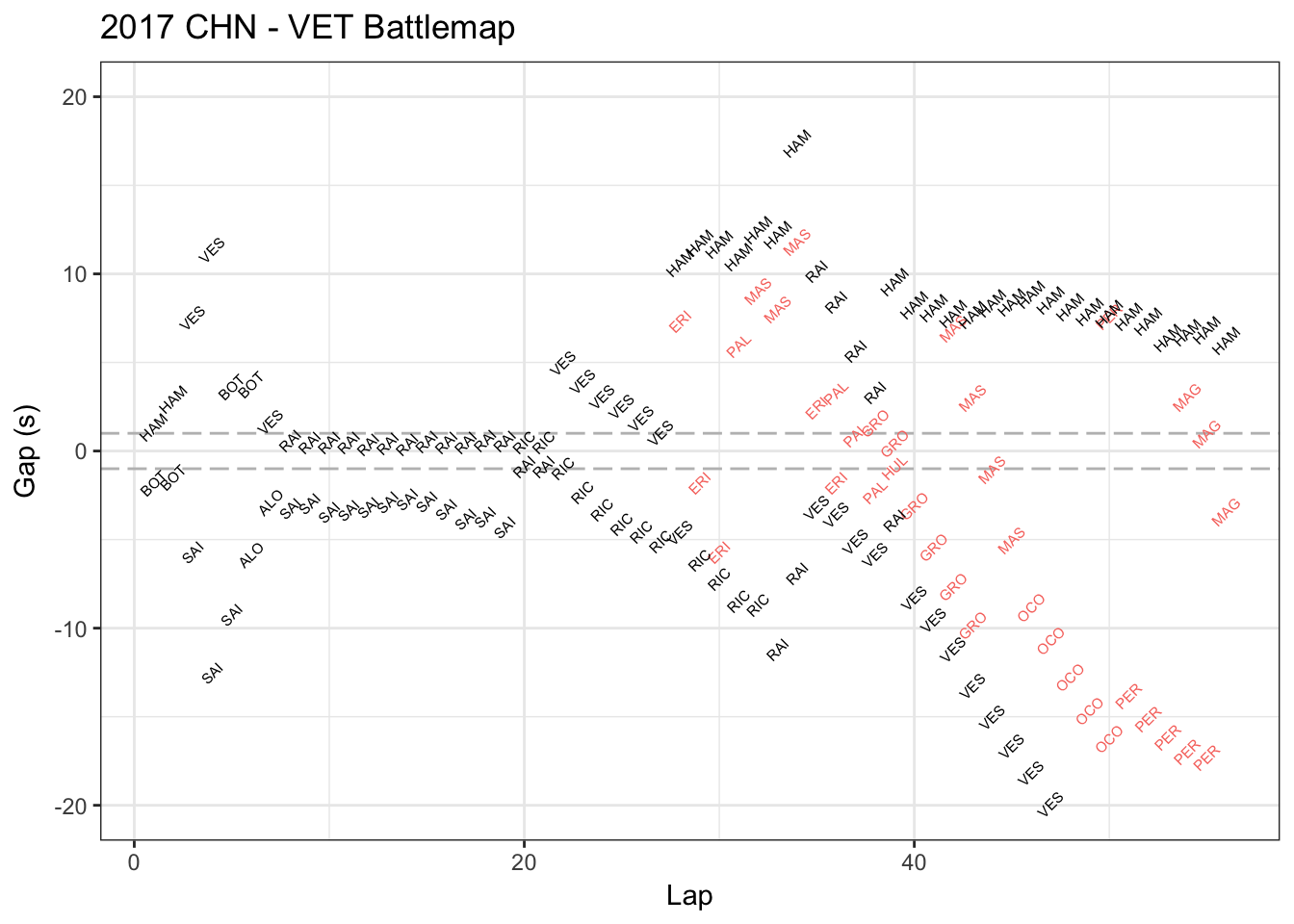 This is Vettel’s race battle map in China Grand Prix in Apr.9 2017. This map shows who’s ahead or behind Vettel and how much the seconds in each lap. The red data represents the players lapped by Vettel.
This is Vettel’s race battle map in China Grand Prix in Apr.9 2017. This map shows who’s ahead or behind Vettel and how much the seconds in each lap. The red data represents the players lapped by Vettel.