In a beautiful and apt analogy, Stephen Few, the Principal of Perceptual Edge encapsulates the purpose of data visualizations – Visualisations are just tools. Just as tools made it easier to build houses, visualization make it easier to portray complicated data. The purpose of visualizing data is served if and when it takes the burden of effort off the brain and puts it on the eyes. In order to accomplish that, he recommends a few core principles:
SIMPLIFY – Perhaps the most important of all, simplification of complicated data should be the first purpose of any data visualization. Choosing the apt type of representation and adding only the most essential/important of data helps in simplifying the complicated data. Care should be exerted to make sure that this does not come at the cost of oversimplifying and omission of important data.
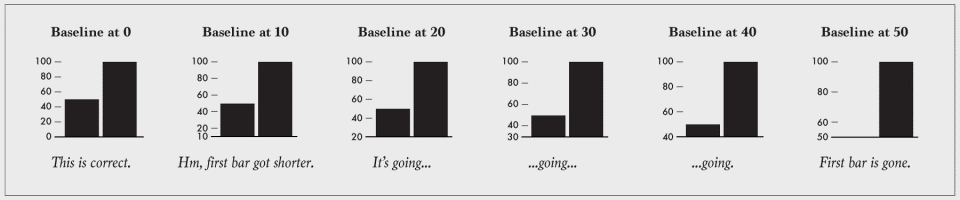
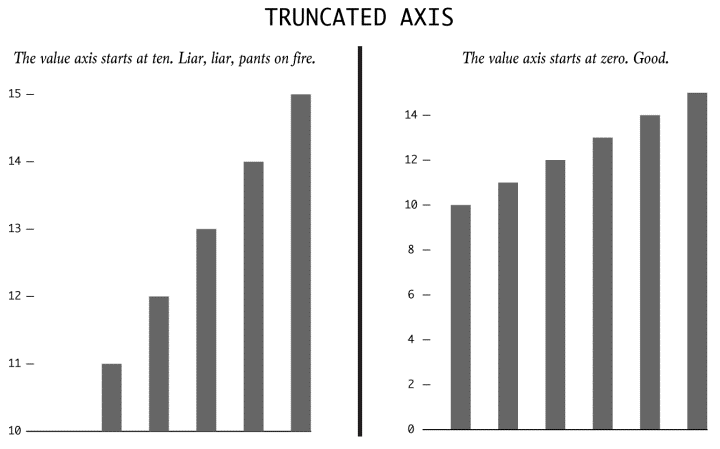
COMPARISON – When using data visualization techniques to compare and contrast two sets of data, it is essential to juxtapose them to offer an easier comparison. Human brain finds it difficult to keep the comparison data in memory and it is cumbersome to have to turn back every other second for comparison.
ATTEND – Visualisation of data should be done in such a way that the audience process the most important data at the first glance itself. Highlighting the important part of the data or using tools and techniques to emphasize the principal parts would serve this purpose admirably.
EXPLORE – A good data visualization should enable the viewer to gather the data it was meant to portray just by looking at it. It should also be flexible enough to allow a directed or exploratory analysis with ease. A good visualization tool must be designed keeping this in mind as well.
DIVERSITY – A data visualization may have different facets to the data it is representing. Different views of the same data may provide different insights. The quality and efficiency of data visualization increase if it allows for the same data to be analyzed from different perspectives and to see the relation between them.
THE WHYs OF DATA – In addition to showing the data, an ideal data visualization should also encourage the viewer to find an answer to the reason/cause behind the distribution of data.
SOLUTION TO POSSIBLE QUESTIONS – Most of the time, viewers take in the data given in the visualization without any question. But a good data visualization should be designed in such a way that it would be able to answer any potential questions. This could be achieved by incorporating more filters and/or software.
In Stephen Few’s words, the best software is the one which you don’t realize that you are using. By putting these basic principles in practice, anyone can design such an efficient data visualization tool.