In the previous post we saw what an svg element is how to define it, what the domain through the xAxis and yAxis and range through xRange and yRange are how to fit it according to the data set.
Next is to transform the xRange and the yRange into the plotting space and draw a line across the plotting space.
This function d3.svg.line() is used to draw a line graph for which we need to create a line generator function which returns the x and y coordinates from our data to plot the line. How is this line generator function defined?
var lineFunc = d3.svg.line()
.x(function(d) {
return xRange(d.x);
})
.y(function(d) {
return yRange(d.y);
})
.interpolate(‘linear’);
The .interpolate(‘linear’) function call tells d3 to draw straight lines. Next step is to set the ‘d’ attribute of the svg path(as mentioned in the xRange and yRange) to the coordinates returned from the line function.
vis.append(‘svg:path’)
.attr(‘d’, lineFunc(lineData))
.attr(‘stroke’, ‘blue’)
.attr(‘stroke-width’, 2)
.attr(‘fill’, ‘none’);
As we can see above the line color is set using stroke, line width set using stroke-width, fill is also set to none so that the graph boundaries are not filled.
Next step is to create the bar chart. As seen earlier the axes has already been created hence we just need to modify the exiting code a bit.
yAxis = d3.svg.axis()
.scale(yRange)
.tickSize(5)
.orient(“left”)
.tickSubdivide(true);
The yAxis starts at 5 because 5 is the minimum y value of the sample data. Hence yAxis needs to scaled from 0. Hence the yRange function needs to be modified like this:
yRange = d3.scale.linear().range([HEIGHT – MARGINS.top, MARGINS.bottom]).domain([0,
d3.max(barData, function(d) {
return d.y;
})]);
In case of bar charts ordinal scales help maintain a discrete domain hence we will be using ordinal scales instead of linear. rangeRoundBands helps in dividing the width across the chart bars. The spacing between the bars are set to be 0.1 can be altered according to user’s preference. Hence the final xRange is defined as:
xRange = d3.scale.ordinal().rangeRoundBands([MARGINS.left, WIDTH – MARGINS.right], 0.1).domain(barData.map(function(d) {
return d.x;
}));
Next step is to create rectangular bars for the chart data. Our sample data will be bound to the rectangles using x and y coordinates to set the height and width of the rectangular bars.
vis.selectAll(‘rect’)
.data(barData)
.enter()
.append(‘rect’)
.attr(‘x’, function(d) {
return xRange(d.x); // sets the x position of the bar
})
.attr(‘y’, function(d) {
return yRange(d.y); // sets the y position of the bar
})
.attr(‘width’, xRange.rangeBand()) // sets the width of bar
.attr(‘height’, function(d) {
return ((HEIGHT – MARGINS.bottom) – yRange(d.y)); // sets the height of bar
})
.attr(‘fill’, ‘grey’); // fills the bar with grey color
Final step is to set the CSS properties of few of the elements.
.axis path, .axis line
{
fill: none;
stroke: #777;
shape-rendering: crispEdges; // provides hint on what tradeoffs to make as the browser renders the path element or basic shapes
}
.axis text
{
font-family: ‘Arial’;
font-size: 13px;
}
.tick
{
stroke-dasharray: 1, 2; //this property helps css in creating dashes in the stroke of the Svg shapes
}
.bar
{
fill: FireBrick;
}
Finally our bar chart from the sample data is ready, with all the styling elements. A detailed version of the code base is available here:
http://codepen.io/jay3dec/pen/fjyuE
Hope this post encourages you all to try a simple bar chart on D3.js.
Reference : https://www.sitepoint.com/creating-simple-line-bar-charts-using-d3-js/



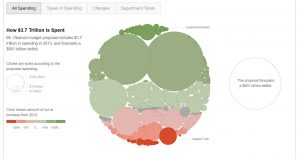 It gives four distinct views of what the budget looks like and the transition between the views is excellent as the existing bubble itself divides into the two types which helps the user look at the underlying data from a different perspective. The size of the bubble is proportional to the amount of money allocated. The color combination is also apt with green showing increase in money from 2012 and red showing corresponding decrease.
It gives four distinct views of what the budget looks like and the transition between the views is excellent as the existing bubble itself divides into the two types which helps the user look at the underlying data from a different perspective. The size of the bubble is proportional to the amount of money allocated. The color combination is also apt with green showing increase in money from 2012 and red showing corresponding decrease.