Visualization is a powerful tool that can help tell a story, simplify a complicated data set and make it easy to identify patterns behind those complicated numbers through visual representation. However, if not used judiciously it can very easily over complicate simple things. Visualization is a means to an end and not an end in itself. The goal is not create a stunning visualization but to create a visualization that conveys the intended meaning and in an effective way. The key word is: “EFFECTIVE”
Designing an effective data visualization comes down to a lot of small details that can be the difference between an effective or a lousy visualization. Attention to detail, identifying and understanding your audience and making sure the various elements are aligned and consistent are some such details.
http://s32.photobucket.com/user/nsrivastava/media/Blog2_image_zpsypuxv39s.png.html
figure 1. Viz_1
The above example can perfectly describe the meaning of overuse of visualization tools available at one’s disposal. The above image intends to show the number of paid paternity leaves guaranteed to people in a given set of countries relative to US, which has none.
However, there are multiple issues with the above visualization which makes it ineffective. Let’s examine the following three major issues:
- Clutter
Clutter means over complicating things when there is no need. In the above example the different sized pie chart pieces do not add any value to the visualization as they do not provide any new insights that are not otherwise available. Its just adds to confusion diverting the audience’s attention.
- Color
Color can be used in a number of ways to convey a point, provide emphasis or compare and contrast different data points. It can also be employed to direct your audience’s eyes to where you want them to go. Color should be used strategically to drive across your point and not to simply beautify the visualization. In the above example, the color instead of making things simpler is complicating it. On first glance, the orange color representing Australia, Venezuela, Kenya and Denmark makes them look like a single country. If one goes by color, it looks like there are only 6 countries being compared.
- Consistency
The data points regarding the guaranteed paternity leave changes from days to weeks. For half the countries the number represents weeks and for the rest, the number represents days. This inconsistency can lead to confusion. For example what does the zero in the center of circle with map of US indicates? Is it 0 weeks or 0 days? Also, representing US as a circle in the center while the rest of the countries are represented as pie chart pieces also indicates inconsistencies. It may confuse the audience into thinking that US is not a country or that it is in some way different from the rest of the countries. However, all that the visualization intends is to represent the numbers relative to US.
Following is an attempt to solve the above issues with a different interpretation of the same data.
http://i32.photobucket.com/albums/d27/nsrivastava/Blog2_img2_zpswgfbq5ip.png
Figure 2: Viz_2
This second visualization better represents the data for the following reasons:
- Distinct color for each country and a clear legends allows the audience to clearly distinguish each country
- The sorted bar graph clearly indicates US at the lowest level with 0 days of guaranteed paternity leaves with Iceland leading the pack with the highest number of paid leaves at 90 days
- The paid paternity leaves are represented in number of days for all the countries so that the information is consistent across the visualization making it easy to compare.
- The numbers on the bars clearly indicate the actual figures leaving no place for ambiguity or confusion.
References:
https://icharts.net/blog/data-expert-spotlight/data-visualization-essential-info-industry-thought-leader
http://viz.wtf/image/158594346945
http://www.flexmanage.com/2017/03/15/5-ways-for-powerful-data-visualizations/
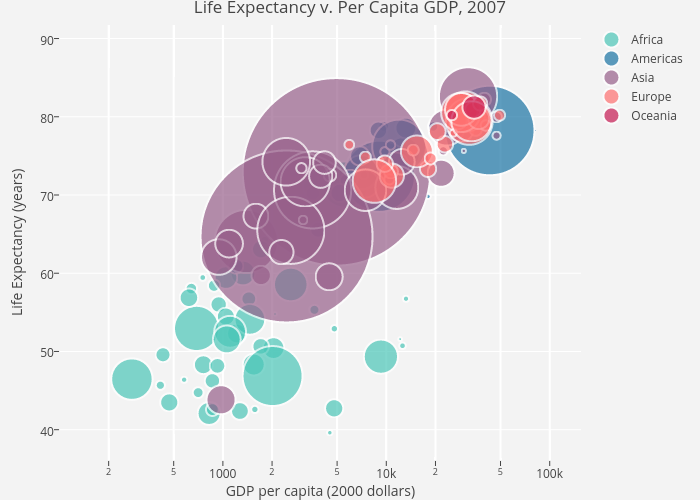
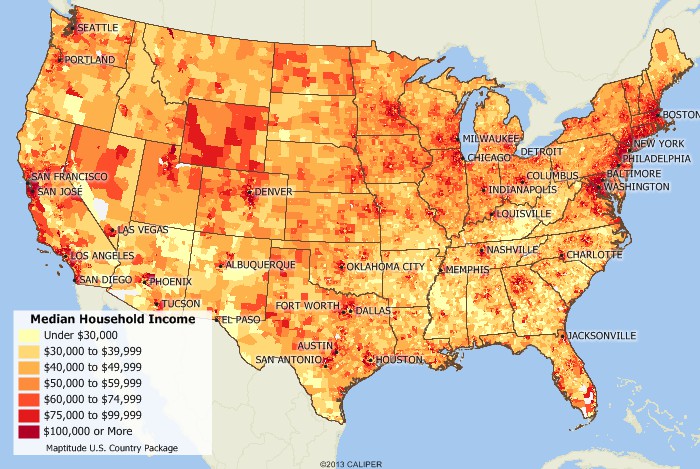


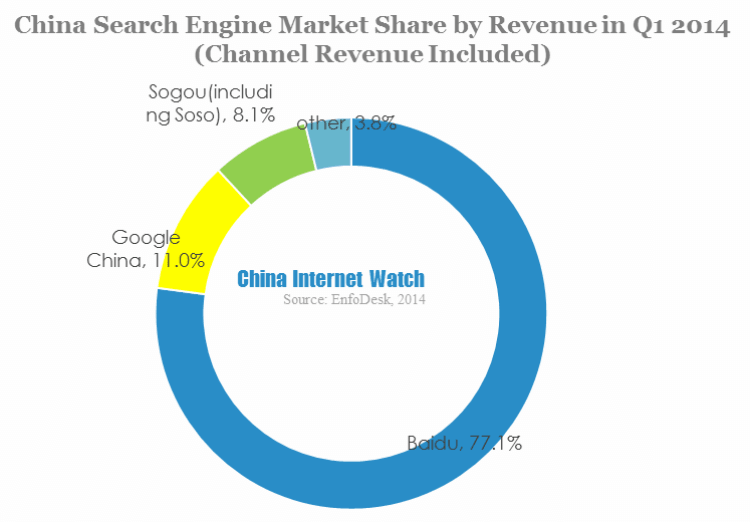
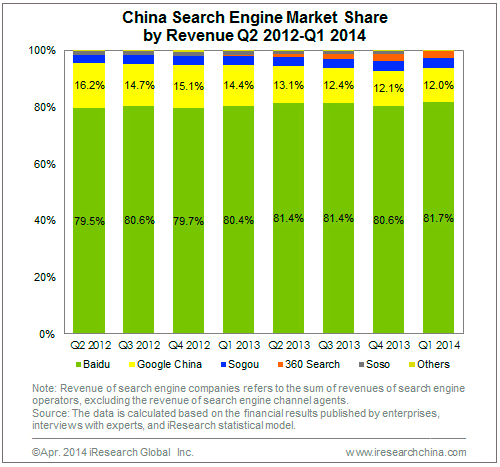

 and Wallet Hub’s:
and Wallet Hub’s:  maps of state tax data.
maps of state tax data.




{kind=link}
{kind=link}